Architecture¶
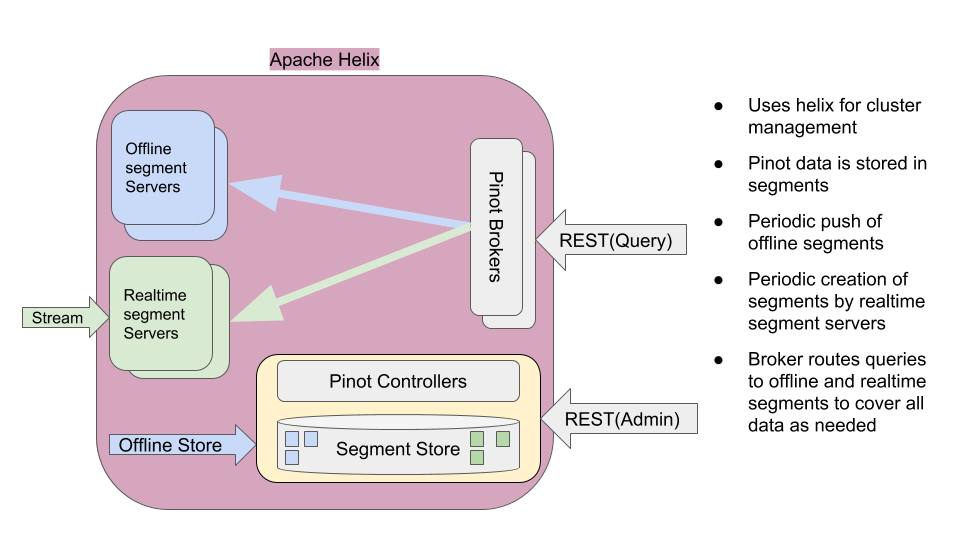
Pinot Architecture Overview
Terminology¶
- Table
- A table is a logical abstraction to refer to a collection of related data. It consists of columns and rows (documents).
- Segment
- Data in table is divided into (horizontal) shards referred to as segments.
Pinot Components¶
- Pinot Controller
- Manages other pinot components (brokers, servers) as well as controls assignment of tables/segments to servers.
- Pinot Server
- Hosts one or more segments and serves queries from those segments
- Pinot Broker
- Accepts queries from clients and routes them to one or more servers, and returns consolidated response to the client.
Pinot leverages Apache Helix for cluster management. Helix is a cluster management framework to manage replicated, partitioned resources in a distributed system. Helix uses Zookeeper to store cluster state and metadata.
Briefly, Helix divides nodes into three logical components based on their responsibilities:
- Participant
- The nodes that host distributed, partitioned resources
- Spectator
- The nodes that observe the current state of each Participant and use that information to access the resources. Spectators are notified of state changes in the cluster (state of a participant, or that of a partition in a participant).
- Controller
- The node that observes and controls the Participant nodes. It is responsible for coordinating all transitions in the cluster and ensuring that state constraints are satisfied while maintaining cluster stability
Pinot Controller hosts Helix Controller, in addition to hosting REST APIs for Pinot cluster administration and data ingestion. There can be multiple instances of Pinot controller for redundancy. If there are multiple controllers, Pinot expects that all of them are configured with the same back-end storage system so that they have a common view of the segments (e.g. NFS). Pinot can use other storage systems such as HDFS or ADLS.
Pinot Servers are modeled as Helix Participants, hosting Pinot tables (referred to as resources in helix terminology). Segments of a table are modeled as Helix partitions (of a resource). Thus, a Pinot server hosts one or more helix partitions of one or more helix resources (i.e. one or more segments of one or more tables).
Pinot Brokers are modeled as Spectators. They need to know the location of each segment of a table (and each replica of the segments) and route requests to the appropriate server that hosts the segments of the table being queried. The broker ensures that all the rows of the table are queried exactly once so as to return correct, consistent results for a query. The brokers (or servers) may optimize to prune some of the segments as long as accuracy is not satisfied. In case of hybrid tables, the brokers ensure that the overlap between realtime and offline segment data is queried exactly once. Helix provides the framework by which spectators can learn the location (i.e. participant) in which each partition of a resource resides. The brokers use this mechanism to learn the servers that host specific segments of a table.
Pinot Tables¶
Pinot supports realtime, or offline, or hybrid tables. Data in Pinot tables is contained in the segments belonging to that table. A Pinot table is modeled as a Helix resource. Each segment of a table is modeled as a Helix Partition,
Table Schema defines column names and their metadata. Table configuration and schema is stored in zookeeper.
Offline tables ingest pre-built pinot-segments from external data stores, whereas Reatime tables ingest data from streams (such as Kafka) and build segments.
A hybrid Pinot table essentially has both realtime as well as offline tables. In such a table, offline segments may be pushed periodically (say, once a day). The retention on the offline table can be set to a high value (say, a few years) since segments are coming in on a periodic basis, whereas the retention on the realtime part can be small (say, a few days). Once an offline segment is pushed to cover a recent time period, the brokers automatically switch to using the offline table for segments in _that_ time period, and use realtime table only to cover later segments for which offline data may not be available yet.
Note that the query does not know the existence of offline or realtime tables. It only specifies the table name in the query.
Ingesting Offline data¶
Segments for offline tables are constructed outside of Pinot, typically in Hadoop via map-reduce jobs and ingested into Pinot via REST API provided by the Controller. Pinot provides libraries to create Pinot segments out of input files in AVRO, JSON or CSV formats in a hadoop job, and push the constructed segments to the controlers via REST APIs.
When an Offline segment is ingested, the controller looks up the table’s configuration and assigns the segment to the servers that host the table. It may assign multiple servers for each servers depending on the number of replicas configured for that table.
Pinot supports different segment assignment strategies that are optimized for various use cases.
Once segments are assigned, Pinot servers get notified via Helix to “host” the segment. The servers download the segments (as a cached local copy to serve queries) and load them into local memory. All segment data is maintained in memory as long as the server hosts that segment.
Once the server has loaded the segment, Helix notifies brokers of the availability of these segments. The brokers start include the new segments for queries. Brokers support different routing strategies depending on the type of table, the segment assignment strategy and the use case.
Data in offline segments are immmutable (Rows cannot be added, deleted, or modified). However, segments may be replaced modified data.
Ingesting Realtime Data¶
Segments for realtime tables are constructed by Pinot servers. The servers ingest rows from realtime streams (such as Kafka) until some completion threshold (such as number of rows, or a time threshold) and build a segment out of those rows. Depending on the type of ingestion mechanism used (stream or partition level), segments may be locally stored in the servers or in the controller’s segment store.
Multiple servers may ingest the same data to increase availability and share query load.
Once a realtime segment is built and loaded the servers continue to consume from where they left off.
Realtime segments are immutable once they are completed. While realtime segments are being consumed they are mutable, in the sense that new rows can be added to them. Rows cannot be deleted from segments.
See Consuming and Indexing rows in Realtime for details.
Pinot Segments¶
A segment is laid out in a columnar format so that it can be directly mapped into memory for serving queries. Columns may be single or multi-valued. Column types may be STRING, INT, LONG, FLOAT, DOUBLE or BYTES. Columns may be declared to be metric or dimension (or specifically as a time dimension) in the schema.
Pinot uses dictionary encoding to store values as a dictionary ID. Columns may be configured to be “no-dictionary” column in which case raw values are stored. Dictionary IDs are encoded using minimum number of bits for efficient storage (_e.g._ a column with cardinality of 3 will use only 3 bits for each dictionary ID).
There is a forward index for each column compressed appropriately for efficient memory use. In addition, optional inverted indices can be configured for any set of columns. Inverted indices, while taking up more storage, offer better query performance.
Specialized indexes like StartTree index is also supported.